中原裕之 (理化学研究所・脳科学総合研究センター・脳数理研究チーム)
はじめに
ここに報告する研究は、彦坂興秀博士(NIH)と私(中原裕之)のひょんな会話から始まった。長年の共同研究の中で、絶えず様々な議論をしていたある日、ドーパミン神経細胞のあるデータを見せられ、こんなデータがあるのだけど何か面白いねというのが始まりだった(彦坂氏がNIHに移ってしまって、以前ほど頻繁に議論できないのが残念であるが、現在でも共同研究は続いている)。ほどなく、それが通常の強化学習のTDモデル(以下の説明参照)では説明できないことが分かった。それから議論を続け、いくつかのデータ解析や、計算機シミュレーション・数理解析を試みたり等、途中経過では色々あった(もちろん、その詳細は省略する!)ものの、最終的な結果は、分かってみれば簡単なことであった。それが今回発表した内容で、分かりやすく(ある意味乱暴に)要約すると、今回分かったドーパミン神経細胞の活動の結果から考えると、どうやら“正しいやる気は、学習を促進するとは本当らしい”ということになる。このことを、以下、順をおって説明したい。
背景
まず簡単に研究の背景・内容・意義について、多少乱暴にはなるが分かりやすくまとめておこう。大脳基底核が、大脳皮質と協力して、複雑な運動の学習・制御に重要な役割を担うことは、知られている。更に、大脳基底核に豊富に存在するドーパミン神経細胞が、予測した報酬と実際に獲得できた報酬の違いを表すような活動、つまり「報酬予測誤差」を表す活動を示すことが、近年発見された。しかも、この活動が、強化学習と呼ばれる計算機アルゴリズム(特に、TD学習(temporal
difference learning)と呼ばれるアルゴリズムのことで、以下では、TDモデルと呼ぶ)で用いられる「報酬予測誤差」という学習信号と非常に似ていることが指摘されました。この事実は、大変な注目を集めています。何故なら、この学習アルゴリズムはかなり強力で、例えば、バックギャモンというゲームでは、この計算機アルゴリズムは、世界レベルの人間のプレーヤーとほぼ同等にプレーできますし、現在、ロボットへの応用も進んでいます。またドーパミン神経細胞の活動は、例えば動機づけされた学習、薬物依存症、あるいはパーキンソン病などの諸々の脳疾患などとも関連します。つまり、この報酬予測誤差を表すドーパミン細胞の活動の性質の解明は、大脳基底核回路の学習・制御メカニズムの解明、生物の優れた学習・認知・運動能力の解明、脳疾患などの解明、あるいは優れた知能ロボットの開発などへの手がかりを与えうると考えられます。
このようにドーパミン細胞が報酬予測誤差を表すらしいことは分かってきたが、実は、その詳細な実態は依然不明です。そもそも、報酬を予測するといっても色々な予測の仕方がある。簡単な例を挙げよう。誰かとじゃんけんをする時に勝つ確率(報酬を得る確率)は、普通は1/2だが、もし相手がパーで引き分けた後には必ずチョキを出すことを知っていれば、勝率は1/2よりも良くなるはずです。このように、うまく適切な手がかりを発見・記憶することができれば、報酬予測の精度が向上する。この報酬予測の精度を向上させられるかどうかは、生物の生存に大変重要です(例えば、もしじゃんけんで買った人しか食事を得られないとしたら、どうです?重要でしょう)。このように報酬予測の精度を向上させられるには、適切な手がかりを発見できる必要があるし、その手がかりをきちんと覚え、かつ適切なときに使えて、不必要なときにはキャンセルし、適時その手がかりを更新できる必要もあります。
今まで実験で確かめられていたドーパミン細胞が表す報酬予測誤差とTDモデルの対応は、いわば、適切な手がかりを利用できない「感覚入力にのみ頼るTDモデル」との対応でした。今回の我々の研究で、実は、ドーパミン細胞は、適切な手がかりを利用した報酬予測に基づく報酬予測誤差を表せること、つまりモデルとしては「文脈を利用できるTDモデル」が必要になることが示されました。
認知・記憶・判断・意思決定・報酬獲得・動機づけなど、これらの機能を完全に切り分けるのは、なかなか難しい。特に報酬を得るための意思決定・動機に基づく学習では、その切り分けは困難です。今回の研究結果は、比較的、報酬獲得・動機付けなどに近いと思われるドーパミン神経細胞の活動が、比較的、認知・記憶などに近いと思われる文脈手がかりに基づく報酬予測を利用できることを示しています。つまりドーパミン神経細胞の活動に既にこれらの機能が入り混じったものが反映されています。このことは、正しいやる気・正しい動機付け・正しい予測が、学習に役立つことを示唆するのかもしれません。もちろん、まだまだ解明すべきことが残っているので、断定できるわけではありません。
研究内容
課題1 (Non-contextual task)
具体的な研究結果を説明しよう。まず最初に見せるのは、今まで行われていた実験課題の典型的な課題で、サルのドーパミン神経細胞の活動を記録したものです。この課題は、古典的な条件付け課題で、各トライアルで、短い光刺激のしばらくした後、50%の確率で、サルは報酬を得ることができます(図1A)。この場合、当然、平均としては50%の報酬が得られることになる。実際の1トライアルでは、50%の予測をしているところで、報酬をもらえるか(この場合、+50%の報酬予測誤差)、まったくもらえないか(−50%の報酬予測誤差)ということになる。これらの±50%の報酬予測誤差にほぼ対応するような反応がドーパミン神経細胞の活動に見られることが分かります(図1A)。
次のこれらの反応をより正確に解析してみました。図1Bに示したのは、報酬のあり・なしのトライアルを別々(太線が報酬あり、点線が報酬なし)にして、そのトライアルの直前までに何回の無報酬のトライアルが続いたか(PRN=post-reward
trial number;言い換えれば、このトライアルまでに、前回の報酬をもらったトライアルから何トライアル既に行っているかを示す)を横軸にしてプロットしました。ここで興味深いのは、両方の線が、正の傾きをもっていることです。なぜなら、この実験課題では、直前のトライアルまで、何があろうと、各トライアルでは報酬の確率が50%です(それゆえ、Non-contextual
taskと呼ばれます)。それならば、何があろうと、±50%の報酬予測誤差になるはずです。それなのに、正の傾きが現れています。なぜでしょう?
実は、このことは、TDモデルの仮説からは、予想されることなのです(図1C,D)。仮説では、ドーパミン神経細胞の活動が報酬予測誤差を表し、それを学習信号とする強化学習に使われる、そして、その学習が各トライアルで少しずつ進むと考えます。実は、実際の実験課題では、確かに平均では50%の報酬確率でも、たまたま報酬(あるいは無報酬)のトライアルが数回続くことはいくらでもあります。つまり、その数回の局所的に限ると、報酬確率は必ずも50%ではありません。このような局所的な報酬確率のゆらぎが、学習を通じてドーパミン神経細胞の活動に反映すると考えられるのです。ちなみに、このことは、仮説から予想されることではありますが、これを実際の実験データで示したのは、我々が世界で最初です。
要約すれば、ともかくこの課題を通じて、我々は、今までの「感覚入力にのみ頼るTDモデル」が、今まで使われていた実験課題においては、ドーパミン細胞の活動と、trial
by trialのバリエーションを含めて、対応が良くつくことを確認しました。
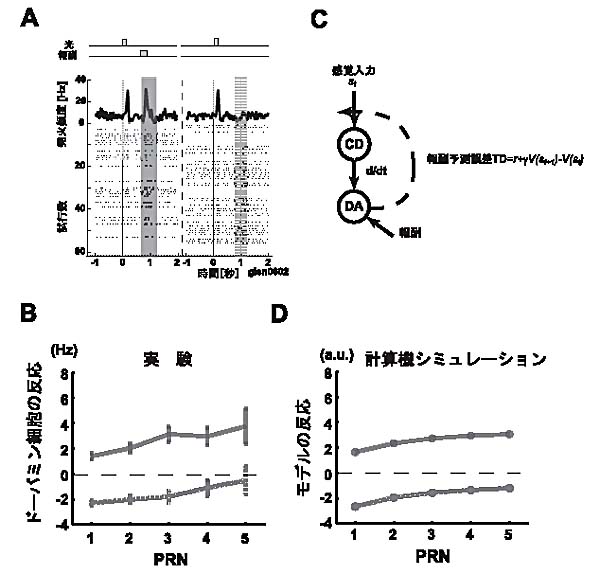 |
図1.
課題1(Non-contextual task)でのドーパミン神経細胞の反応と「感覚入力にのみ頼るTDモデル」 |
課題2 (Contextual task)
この課題は、記憶誘導性眼球運動課題(memory-guided saccade task)です(図2A)。サルの具体的な行動手順は図を見ていただくとして、ここで重要なのは、各トライアルでは、4方向のうち1方向が視覚刺激(キュー)によって指示されて、サルはその方向に眼球運動をしなければならないということと、たとえ正しく眼球運動したとしても、サルが報酬を実際にもらえるのは4方向のうち1方向のみだということです(各実験プロックごとに報酬をもらえる方向が代えられて、そのブロック内ではその方向に固定されます)。ですので、報酬をもらえる確率は25%、平均の報酬予測も25%となります。ドーパミン神経細胞のキューに対する反応は、おおよそこれに従っている(図2B;左が報酬、右が無報酬)。この課題では、各トライアルで、キューが出されるた後には、報酬がもらえるかもらえないのかは100%はっきりします。ですので、報酬方向を示すキューに対しては+75%の予測誤差、無報酬方向に対しては−25%の予測誤差を表すことになる。
この活動を、先ほどのPRNを使って、より詳細に示したのが図2C,Dです。図2Cが、実験初期の活動で、図2Dが実験後期の活動です。二つ気づくことがあります。まず第一に、実験初期と後期で活動のパターンがまったく変わっていることが分かります。次に、より重要なのは、実験後期では両方の線の傾きが負になっており、さきほどの課題1の傾きと全く逆になっています。なぜでしょうか?
実は、この実験課題では、PRNの数によって報酬確率が変化するようになっています。PRNの数が小さいほど、報酬確率が小さいようになっているのです。つまり、平均の報酬確率は確かに25%ですが、PRNを手がかりにする報酬確率(数学的には、PRNに対する条件付報酬確率と言います)が変化します。これに基づいて考えると、大雑把には次の三つのことが分かります。第一に、実験初期の反応は、ほぼ平均の報酬確率に基づき予測誤差を出していること。第二に、実験後期には、条件付確率に基づき、予測誤差を出していること。PRNが小さいときには報酬確率は低いため、実際の報酬があると、“より驚く”、つまりより大きな報酬予測誤差を表していると考えられるからです。第三に、このように手がかりを使う報酬予測は、実験課題を経験するなかで、サルが自らその手がかりを発見し、利用できるようになったということも示しています。
ただ実際には、課題1で見たような学習による効果、局所的な報酬確率のゆらぎの効果があるので、より定量的に見ることが必要不可欠です。まず、「感覚入力にのみ頼るTDモデル」では、このドーパミン神経細胞の活動を表すことができないのは明らかです(図2E,G)。それゆえ、適切な手がかり、つまり「文脈を利用できるTDモデル」を新たに構築してみると、このモデルの反応が、実験後期の活動と大変よく対応がつくことが分かります(図2F,H)。なお、より詳細なレベルでも、この対応があることも確認しました(原論文の図5参照)。
まとめると、この課題1と課題2を通じて、ドーパミン神経細胞の活動が、適切な手がかりを利用した報酬予測の誤差を表現しうることが分かりました。更に、その活動が「文脈を利用できるTDモデル」の予測誤差と対応がつくことも分かりました。今後に関する研究としては、様々なことが挙げられますが、紙面も尽きてきたので、列挙は差し控えます。
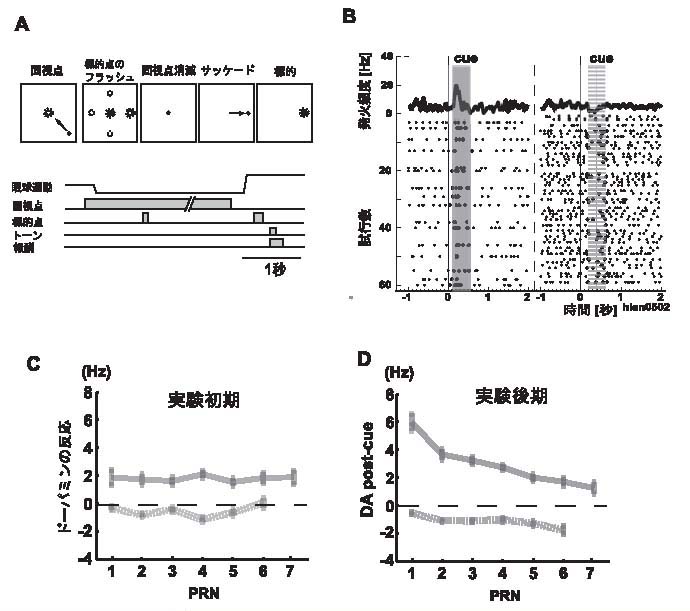 |
図2.
課題2(Contextual task)でのドーパミン神経細胞の反応と「文脈を利用できるTDモデル」 |
最後に
もっと詳しく知りたいですか?どうか論文を読んでみてください。面白がってもらえると嬉しく思います。最後に、この研究は、絶えず楽しく議論してくださる彦坂氏、そして見事な実験をされた川越順子、滝川礼子氏(順天堂)、また理論的側面を一緒に研究している伊藤秀昭氏(東工大)らとの共同研究であり、実験・理論の双方が重要な役割をした研究であり、全てのメンバーが重要な役割を果たしたことを述べておきたいと思います。「先端脳」のように、実験・理論の研究者が深く議論できる場があってこそ、やり得た研究だと思います。
|
